
Object detection for mobile robots in manufacturing environment
April 8, 2022
Manufacturing environments are inherently unstructured and unexpected changes can significantly reduce efficiency and increase overall manufacturing time. Thereupon, the ability of manufacturing entities, such as mobile robots, to adapt to these changes and stochastic processes in a highly dynamic manufacturing environment is of utmost importance. Mobile robots should be equipped with a robust vision system that can detect and track other dynamic manufacturing entities. Therefore, the implementation of an object detection system based on Convolutional Neural Networks (CNNs) represents a logical solution.

Object detection implies detection and tracking of multiple objects in images. Prior to multiple object detection (Fig. 1), whole images were classified without the knowledge of where exactly in the image is the location of the classified object. A step closer to object detection, as we know it today, was image classification with object localization. In this case, the location of an object in the image is defined by a Bounding Box (BB) which is a vector with four values (i.e., a center of bounding box – x and y coordinate, height and width of the bounding box) that are normalized, and in the range of 0 to 1. When CNN is trained to detect more than one class of objects, the first value in the output vector (i.e., BB) represents the object class, and additionally, it can contain the confidence of a prediction (Fig. 2).

One instance of object localization with outputted bounding box values marked green is shown in Fig. 3

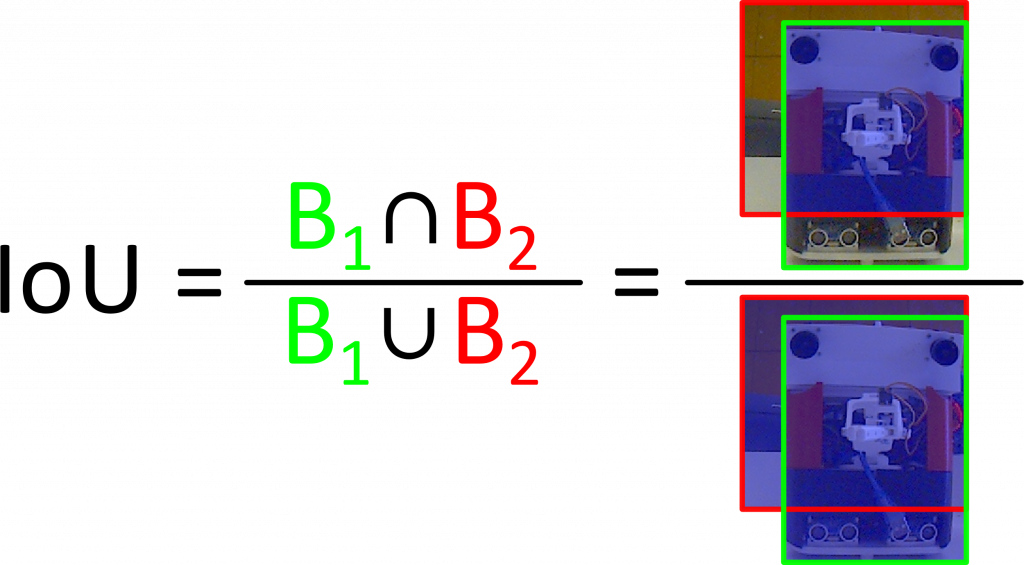
The confidence prediction is defined by Intersection over Union (IoU), and this metric is used to evaluate how much does predicted BB overlap with ground truth BB (Fig. 4). The standard confidence threshold is 0.5 and all confidence values over this threshold are considered a good match. There can be multiple overlapping BB predictions of the same object, so to determine the best matching BB non-max suppression is used. Non-max suppression technique removes all BB predictions below the defined confidence threshold and keeps BB predictions with the highest confidence. Furthermore, if there are BBs overlapping with BB that have the highest confidence (IoU of these BBs are over 0.5), those overlapping BBs with lower confidence values will also be removed.
Creating and designing CNN for object detection can be a challenging task and this is where transfer learning comes into play. Transfer learning represents the common practice in training CNNs for object detection and is a way to utilize and retrain existing CNN architectures with new training data and already existing weights. Two major benefits of transfer learning are the ability to use higher learning rates for training and reduced training time as convergence is faster due to the fact that weights are not randomly initialized. Some of the most used and accurate CNNs for object detection are YOLO [1], R-CNN [2], and SSD [3].
The main difference between the aforementioned CNNs for object detection is the way BBs predictions are performed. Regarding BB predictions there is a tradeoff between the speed and accuracy of these models. R-CNN architecture utilizes the region proposal technique which offers slightly higher accuracy at the expense of the speed of detection, while the other two CNN architectures can be used for real-time implementation and offer similar accuracy as R-CNN with much faster detection.
An example of the real-time multiple object detection made with the stereo vision system of the mobile robot DOMINO (Deep learning-based Omnidirectional Mobile robot with Intelligent cOntrol) and with the utilization of YOLOv5s [4] CNN architecture is shown in Fig. 5.

References:
- Redmon, Joseph, et al. “You only look once: Unified, real-time object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
- Liu, Wei, et al. “Ssd: Single shot multibox detector.” European conference on computer vision. Springer, Cham, 2016.
- Glenn Jocher, Ayush Chaurasia, Alex Stoken, Jirka Borovec, NanoCode012, Yonghye Kwon, TaoXie, Jiacong Fang, imyhxy, Kalen Michael, Lorna, Abhiram V, Diego Montes, Jebastin Nadar, Laughing, tkianai, yxNONG, Piotr Skalski, Zhiqiang Wang, … Mai Thanh Minh. (2022). ultralytics/yolov5: v6.1 – TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference (v6.1). Zenodo. https://doi.org/10.5281/zenodo.6222936