
Generative Adversarial Networks for one-dimensional data
August 30, 2022
Successful employment of data-driven solutions, particularly based on deep learning approaches usually requires a big amount of data. However, due to various limitations in the acquisition of data from the real process, its availability is still a major challenge. For instance, the Industry 4.0 factory implies frequent reconfiguration which reduces the time intervals available for experimental procedures such as data acquisition. One of the ways to deal with this issue is called data augmentation [1].
Data augmentation sometimes, e.g. in the case of an image, can be achieved by simply rotating or mirroring the image, however, such approaches may still not be enough for more complex problems. For this reason, Generative Adversarial Networks (GAN) were developed to increase the amount of data by using existing data [2]. Although GAN has often been applied in image-based applications, it can also be effectively employed in the case of one-dimensional data. GAN represents a method for creation of generative model using adversarial process. GAN consists of two players:
- Generator G that has the goal to generate data with the distribution close to the distribution of training data (Fig. 1a), and
- Discriminator D with the goal to recognize if the data is created by generator or comes from the original dataset through classification of input as real or generated (fake) data (Fig. 1b).
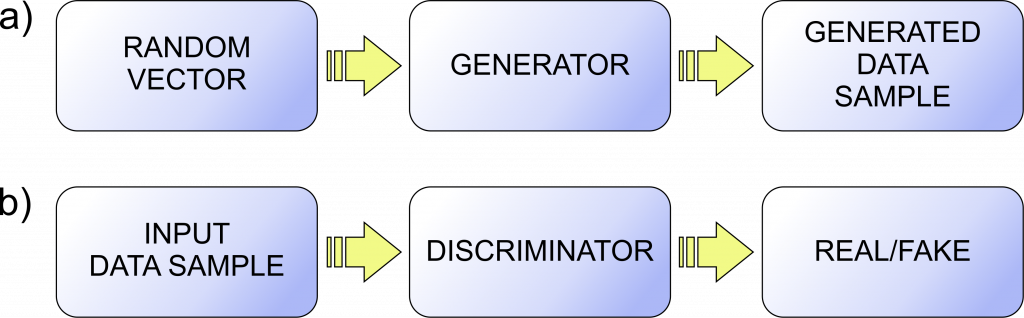
GAN training is a two player adversarial game in which generator generates fake data and tries to force discriminator to make a mistake and to recognize this data as real [3, 4]. As a rule, at the generator input is a vector of random numbers (vector of latent variables) and at its output is multidimensional vector that represents the generated data (Fig. 1a). This data is at the input into discriminator, whereas at the discriminator output is a scalar which represents the probability that the input data is real and classifies the input accordingly (Fig. 1b). Generator and discriminator are trained simultaneously, where generator creates a batch of fake samples that are along with a batch of real samples from training dataset put to discriminator to classify them [3]. Based on the quality of discriminator’s classification, the generator is updated to create “better” fake data and discriminator is updated to perform better classification. This adversary game repeats for a predefined number of iterations.
Generator and discriminator can be in the form of different ML based models. In the example from [1], the GAN was designed using the different architectures for discriminator (Fig. 2a) and generator (Fig. 2b).
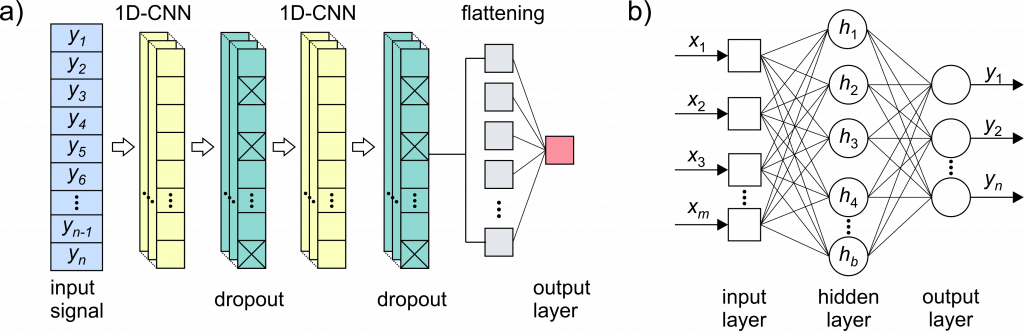
Discriminator architecture contains of two blocks with convolutional layer followed by dropout layer, flattening layer and output (fully connected) layer. At input of discriminator is a generated/real signal with length of n samples and estimation if this signal is generated or real (0/1) is at output.
The generator on the other hand, has the input latent vector of m random numbers, one hidden layer and fully connected output layer with n neurons. The generator generates n samples based on m random numbers. For GAN training a batch of k real signals si, iϵ[0,k-1], with length of n samples each, are extracted from training dataset in the following way:
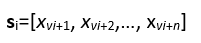
Figure 3 presents an example of signal obtained using the trained generator, as well as the excerpt of signal obtained from real process.
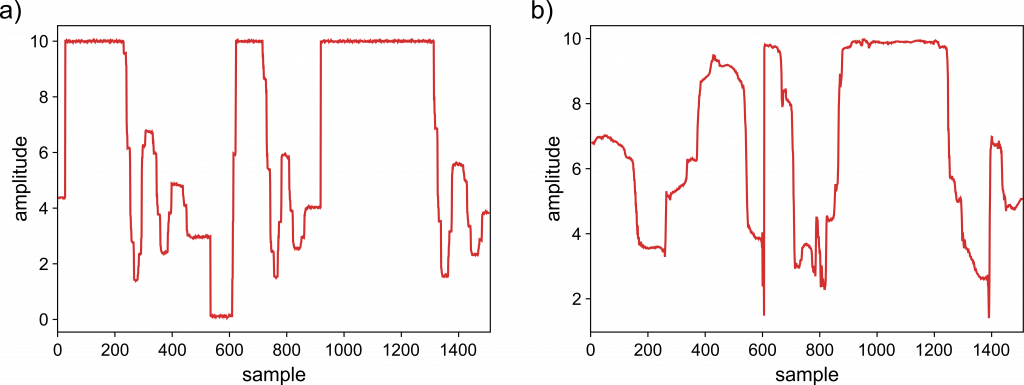
It can be noticed the similarity between the generated (synthetic) and the original signal. One of the great things which data augmentation brings is the ability to generate an unlimited amount of data. In addition to the obvious similarity, as a rule, the distribution of generated data should correspond to the original data distribution. The way to check the quality of the generated data depends on the specific applications for which they are utilized.
References:
- Nedeljković, D., Jakovljević, Ž., GAN-based Data Augmentation in the Design of Cyber-attack Detection Methods, In 9th International Conference on Electrical, Electronics and Computing Engineering (IcETRAN 2022), pp. 669-674, Serbia, 2022.
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, Generative adversarial nets, Advances in neural information processing systems, Vol. 27, 2014.
- J. Brownlee, Generative Adversarial Networks with Python: Deep Learning Generative Models for Image Synthesis and Image Translation. Machine Learning Mastery, 2019.
- F. Chollet, Deep learning with python. Manning, Shelter Island, NY, USA, Nov. 2017.