
Convolutional Neural Networks for Efficient Semantic Segmentation
November 25, 2021
Semantic segmentation represents the process of labeling every pixel in the image with the pixel’s class. Therefore, the image is no longer defined with RGB values but with the semantic map when the semantic segmentation process is performed. Moreover, the image is divided into segments which
represent meaningful objects for humans (see Fig. 1), e.g., tables, chairs, floor, cars, etc. Semantic segmentation is critical in autonomous driving, mobile robotics (scene understanding), and satellite/drone image processing.

The most accurate methods for semantic segmentation are Convolutional Neural Networks (CNNs). There are numerous different CNN models used for semantic segmentation, and the main difference between them is model architecture (number, type, and order of layers). CNNs represent the pyramid-like structure, where consequent layers process the input images, and the output of each layer is called a feature map. The resolution of feature maps is gradually lowered by pooling and convolution layers. Convolution layers have numerous filters with defined 2D sizes. Some of the most popular CNN models for semantic segmentation are FCN, FPN, and DeepLab networks. Even though these models achieve a high level of accuracy on numerous popular datasets, their main disadvantage for real-world implementation lies in their enormous size. These models include millions of parameters and require high-end computation resources to run. Some of those models cannot be implemented in real-time (>=30 FPS), even with high-end computers. Therefore, developing efficient CNN models used for mobile devices is a new hot topic in the research community.
Telephones, mobile robots, drones, and other machines with limited processing capability require the adaptation of “lightweight” CNN models so that they can perform semantic segmentation tasks in real-time. These models need to have low computation costs and occupy less disk space. Therefore, these deep neural networks need to have fewer layers and a smaller number of trainable parameters while still achieving competitive levels of accuracy with larger models. Computation time for the forward pass of the neural network is called inference time, and it represents the main parameters that influence the FPS model can achieve. Promising CNN models that have the potential to be used on mobile devices will be analyzed next.
SegNet
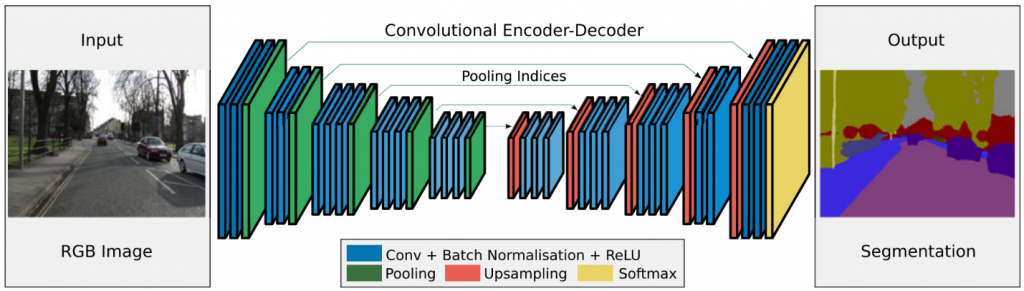
The SegNet model [1] uses symmetric encoder-decoder architecture (Fig. 2) based on the VGG16 network. The encoder represents the first part of the networks where the resolution of feature maps becomes smaller. The decoder is the second part of the network, and it is used to up-sample the features maps generated by the encoder to the original image resolution and output the semantic map. The first significant improvement implemented into the SegNet model is removing fully connected layers, reducing encoder parameters from 134 to 14.7 million. Moreover, the indexes of max-pooling layers in the encoder are stored and used for upsampling in the decoder. That way, pre-trained weights from the original VGG16 network can be used, and a reduction in the memory is achieved.
ENet
One of the first CNN architectures for semantic segmentation that considers the network’s memory footprint and inference speed (i.e., FLoating point OPerations FLOPs) is ENet [2]. One of the principal advances is that early layers (with a small set of filters) heavily reduce the resolution of feature maps since the processing of high dimensional features maps is computation expensive. Another design choice used to improve this model’s inference time is performing the pooling and convolution in parallel (for downsampling) and concatenating the resulting feature maps. In the end, increased efficiency is achieved by modifying the decoder only to have a few layers. All these improvements lead to a more efficient network.
Nvidia TX1 is one of the most powerful commercial single-board computers used for embedded visual deep learning applications. NVIDIA Titan X is one of the high-end GPU-s used for workstations for deep learning. The inference time measured in microseconds of two analyzed networks is compared and presented in Table 1.

As it can be seen, while SegNet can be used in near-real-time fashion on the high-end GPU, it is not as useful for mobile applications where only a single-board computer provides the computing power (e.g., Nvidia TX1). On the other hand, the ENet can provide a reasonable frame rate even on single board computers. It achieves around 20FPS for semantic segmentation of images that have 480×320 resolution. It is also important to note that both SegNet and ENet models achieve similar accuracy on the most popular datasets for semantic segmentation (accuracy of all analyzed models is presented at the end of the post).
ERFNet
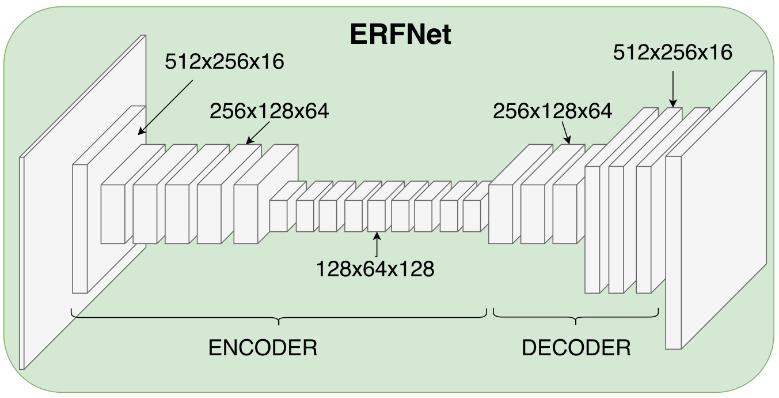
The following network model encoder-decoder structure is entitled ERFNet (Fig 3.) [3]. The authors utilized the ResNet model and modified the convolution process by decomposing 2D convolution into two 1D processes. With this decomposition, they significantly reduced the required parameters and, therefore, the processing time. For the most commonly used 3×3 convolution layer, the decomposition to two layers with 1×3 and 3×1 filters yields the reduction of 33% in the number of parameters required for that layer.
Another exciting network architecture is named FarSee-Net [4]. The main idea is to utilize low-resolution images while outputting the high-resolution semantic maps. Standard ResNet18 encoder is used, and the decoder is Cascaded Factorized Atrous Spatial Pyramid Pooling (CF-ASPP) module. Standard ASPP module is made more efficient by separating 3×3 convolution into 1×1 convolution and 3×3 convolution with different aurous rates and entitled F-ASPP. The model is completed (CF-ASPP – Fig. 4) with the addition of a second F-ASPP module used with fewer filters and low-level features generated by the third convolution layer of the encoder.
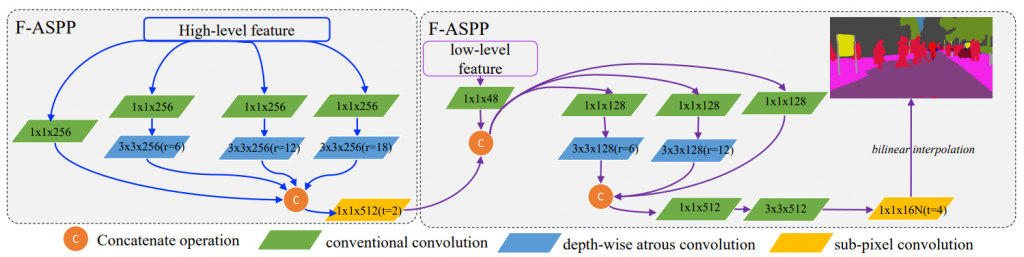
The final output (semantic map) is generated when the output of CF-ASPP is upsampled by sub-pixel convolution [30]. The network is trained with low-resolution images; however, the accuracy is calculated with a high-resolution feature map that has the same resolution as a network output.
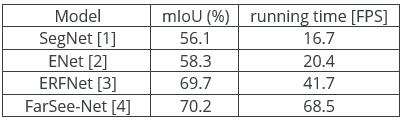
The accuracy (mean Intersection over Union – mIoU) and runtime (FPS) tradeoff of the all analyzed network is presented in the Table 2.
- Badrinarayanan, V., Kendall, A. and Cipolla, R., 2017. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12), pp.2481-2495.
- Paszke, A., Chaurasia, A., Kim, S. and Culurciello, E., 2016. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv preprint arXiv:1606.02147.
- Romera, E., Alvarez, J.M., Bergasa, L.M. and Arroyo, R., 2017. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Transactions on Intelligent Transportation Systems, 19(1), pp.263-272.
- Zhang, Z. and Zhang, K., 2020, May. Farsee-net: Real-time semantic segmentation by efficient multi-scale context aggregation and feature space super-resolution. In 2020 IEEE International Conference on Robotics and Automation (ICRA) (pp. 8411-8417). IEEE.